The ACCORD project addresses the Analysis of Multicore Communication and its Optimization in Real-time Devices. We are investigating a formal performance analysis approach and have applied it to various industrial examples.
The transition of consumer products from SoC to MpSoC is driven by higher performance needs at low power consumption demands. Like in distributed embedded systems, multiprocessing comes at the cost of higher computation and communication complexity. Other than in distributed embedded systems, task communication is overlaid by memory traffic leading to very complex communication patterns including the effects of multithreading and non-blocking memory accesses.
Predicting the timing behaviour of such multiprocessor systems is fundamentally more difficult than in the single processor case: The interaction and correlation between distributed system components, such as a shared memory or coprocessors, makes it nearly impossible to uncover corner cases with purely simulative approaches. Memory accesses are highly dynamic and can routinely lead to overload situations which must be handled by communication mechanisms such as buffering and traffic shaping which have a feedback effect on task execution. It is very difficult if not impossible to systematically create corner cases for simulations that reliably trigger such situations. Even worse, memory access patterns are sensitive to changes in the software code which cannot be appropriately modelled in simulation. This makes it difficult to start system verification at early design phases and plan for later software updates. Thus, a risk remains that the system fails. This risk increases system complexity. Simulation alone simply is not appropriate any more.
At our institute, we have developed a performance analysis tool, SymTA/S, and an appropriate design methodology. This framework can back up a simulation by supplying robust data on cornercase behaviour, and by allowing to quickly explore new design options. It is the basis of the commercial tool that is sold by the spin-off, SymtaVision.
The classic formal performance analysis approach is bottom-up: First, the individual task timing is derived in an isolated (and therefore controllable) environment. This can use simulation, tracing, emulation, or whatever is currently used in the design process. Secondly, this information is coupled with information about the local components (such as the scheduling behaviour and contextswitch times, caches) to derive the local execution behaviour. Finally, all system level influences (such as message delays, accesses to shared resources, or traffic shapers) are considered to produce the overall timing of the system.
This separation of concerns allows each level of abstraction to be investigated separately using more sophisticated methods than in unified approaches. The system level analysis step can quickly evaluate a given setup, identify corner cases and allow designers to optimize the system e.g. for performance or robustness.
In MpSoC, the mentioned system level is entangled with the task level, in the sense that a task’s access to the shared memory is subject to system level influences. Thus, a timing feedback exists.We solve this technical problem by introduction of an extended task model that explicitly expresses shared resource accesses. An automatic iterative analysis derives the joint timing.
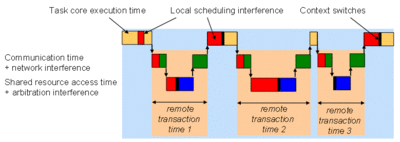
The extended task model is depicted in Fig. 1. In addition to the classical task states “ready” and “finished”, such a task is in the “waiting” state when it has initiated a “transaction” to a shared resource that supplies data or services that must be finished before the task may continue its execution.The response time of a task is then a composition of local and remote effects: Locally, its core execution time, the amount of local scheduling interference and the context switch times need to be considered; remotely, the transactions will experience network delay and interference on the shared resource/memory.The timing of the individual transactions is highly dynamic. In the case of thousands of memory accesses per task invocation, not every memory access can experience the worst case timing. Therefore, previous approaches which relied on worst-case assumptions, implied an unacceptably high overestimation. We have proposed to consider the timing of all transactions jointly, thereby assuming worst case interference on the transactions distributed over the task’s invocation.
This is a short overview presentation recently held at an ArtistDesign project meeting in April 2009: