The IPF project is a transatlantic collaboration among University of California, Irvine, TU Munich and TU Braunschweig, jointly funded by the Deutsche Forschungsgemeinschaft (German Research Foundation - DFG) and the US National Science Foundation (NSF).
You can find the website of our partners here.
Official DFG project summary
IPF stands for a novel concept in the management of large and complex heterogeneous Multi-Processor Systems-on-Chip (MPSoC) towards autonomously operating embedded and cyber-physical computer systems. Like a smart factory that uses a data-centric infrastructure and AI to integrate production, supply management, facility management, operation and maintenance, IPF envisions an integrated self-management of future connected MPSoC. To that end, IPF uses the principles of self-awareness and cognitive self-organization. It combines the many sources of information from sensors, application profiles and requirements (e.g., safety), expected changes and workload situations to identify potential future MPSoC system failures (“imminent hazards”) and optimize resource usage (e.g., energy) as well as system lifetimes.
IPF has 2 phases. Phase 1 (IPF 1, 2018-2022) focused on the management of an individual MPSoC. It formulated the fundamental challenges, derived terminology and methods, and provided solutions for autonomous operation under long-term safety and availability requirements. The results take continuous alterations into account, like a changing environment, system dynamics, and degradation. Literature and press coverage can be found here. A prominent use case is a pacemaker ["The Information Processing Factory: A Paradigm for Life Cycle Management of Dependable Systems"; Eberle A. Rambo, Thawra Kadeed, Rolf Ernst, et. al.].
The second phase, IPF2.0, (2022-2025) extends the principles and applications to networks of MPSoC systems. In a first stage, multiple MPSoCs are connected via local networks, an infrastructure found in modern vehicles, in aircraft, or in robots. Such systems are still developed in a coherent design process, with a fixed network topology and a single owner. This stage can be likened to combine several production lines in a larger factory, to stay in the factory metaphor. The second stage of IPF 2.0 researches into solutions for orchestrating such local systems in larger multi-owner networks, such as known from industrial supply chains. IPF2.0 uses truck platooning as a related use case, where trucks orchestrate ad hoc to form a loosely coupled system exchanging data for joint operation in traffic.
The IPF2.0 consortium is in close contact to a Korean partner at Kookmin University, that put together a platoon demonstrator and a test environment to evaluate management abilities in a platoon. You can find a demonstrative video of the Kookmin platoon installation here.
As mentioned above, the extension of the application field of the principles developed in IPF1.0 will take place in two stages. In the first stage, we will move from standalone multicore chips to a group of networked processors. As mentioned above, this would be equivalent to different highly automated and self-managed production lines in a factory being integrated. The context of this integration remains within a factory ground with a fixed topology and a shared owner. Applying this to networked MPSoCs, this transition poses some significant challenges to the underlying communication network. Mechanisms of continuous monitoring and self-awareness are key components to handle everchanging environmental and system-specific dynamics. As these are the central mechanisms that allow for a smart self-aware processing factory, they already dominated research in the previous IPF1.0 project on multi-/manycore architecture level. On the level of a networked platform, self-awareness can only be achieved, if data (e.g., meta data like status or reliability information, but also processed data) can be exchanged between the processors in a safe and timely manner. Therefore, the compliance to requirements like timing, performance, and correctness of the data transfer has a significant influence on the safe operation of the whole distributed system.
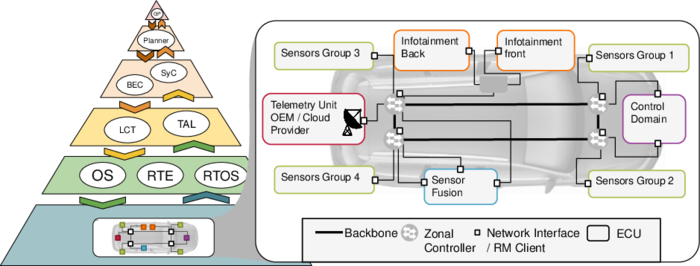
Typically, networks in safety-critical systems like state-of-the-art vehicles are statically configured as locations and availability of data producers (e.g., sensors) and data consumers (e.g., sensor fusion) is known at design time. However, adaptation to dynamic changes within the system is a central mechanism of the information processing factory idea. Metaphorically, processing factories cannot stop operation. Environmental changes and system dynamics endangering the factory process will be identified through monitoring and result in adjustments of the processing line to ensure continuous operation. Enabling a system to self-adapt and adjust its operation improves the system’s longevity significantly. Therefore, in the application field of networked MPSoCs, the network control and data distribution mechanisms shall be broadened to support system dynamics. In safety-critical systems dynamic changes in operation and configurations are not considered, as it substantially complicates safety verification and certification. The concept of a Resource Manager (initially developed in phase 1 of IPF), allows for reconfigurations of the communication network while verifiability remains, and safe operation can be guaranteed at all times.
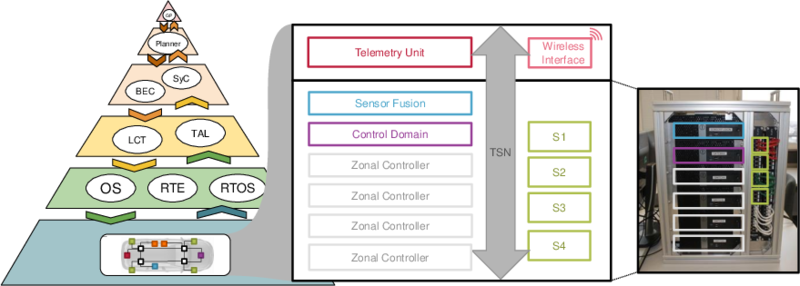
In IPF1.0, a demonstrator of an in-vehicle network was put together to evaluate and verify the Resource Manager’s functionality. This demonstrator will be extended and further utilized in phase 2 of IPF.
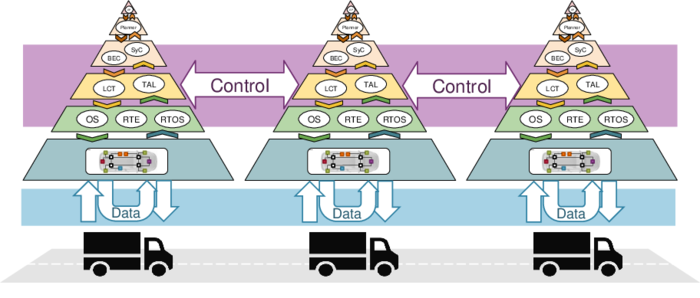
The previously mentioned dynamics are only amplified in stage two, when we consider cooperation of distributed systems. In the processing factory metaphor, this would equal a cooperation of independent factory grounds in different locations or for different stages in the supply chain. Within the IPF2.0 consortium, truck platooning is considered as an example of such a system as already stated. Data distribution in a platoon is even more dynamic, as platoon members can join and leave the platoon frequently and with that, taking or bringing in new data producers or data consumers into a system that is connected by a lossy communication medium only. The IPF2.0 project investigates opportunities to support such dynamism in order to enable or enhance safety-critical applications such as truck platooning. Adjusting and optimizing the data transport in dynamic scenarios supports composability while allowing to improve energy efficiency and performance.
The requirements on traffic in vehicular networks such as those of the trucks in the platooning use case pose as a significant challenge for future vehicular networks due to the dynamism and varying communication semantics. Meanwhile, there are still stringent safety and timing constraints that must be taken into account at all times. At the Institute for Computer and Network Engineering we develop protocols and mechanisms to address this issue.
Optimization of data management with Dynamic NUMA
First, we aim to tackle architectural challenges caused by the high timing and reliability requirements on data availability and data distribution by taking a data-centric perspective. Taking distributed shared memory architectures (with NUMA) into consideration for vehicular systems with multiple distributed ECUs, allows us to introduce caching mechanisms to be used in these distributed systems. Considering the vehicular use case, potentially large objects, such as processed or raw sensor (e.g., Camera or Lidar) data, needs to be exchanged. Limiting data transmission to the truly needed data portions only, can improve the performance but also energy efficiency of the system. A data distribution concept will be developed that allows for fragmental data updates (in line with traditional hardware data caching mechanism found in modern processors) and burst-like object caching transfers (coinciding with publish/subscribe data distribution found in DDS/RTPS). The combined caching mechanism shall adapt the data distribution pattern best fit for the situation and traffic pattern. Further, due to the vast exchange of large data objects caused by the distributed nature of future vehicular computing platforms and the sheer number of sensors in future vehicles, approaches to optimize the data locality and exchange will be examined.
Network management via Resource Manager
To address the increased dynamism we advance the concept of Resource Management (RM). Resource Management is intended for the coordination of applications and network (segments) in order to give guarantees for the data exchange that is essential for safe and timely communication. On the one hand, RM will be used to coordinate all in-vehicle traffic, including streaming and caching. Furthermore, we extend RM to enable inter-vehicle communication between the trucks in a platoon by coordinating the wireless channel.
Reliable Wireless Communications
While the coordination of data streams/traffic on the wireless channel is essential for safe operation, it does not suffice for all encompassing safety considerations. With the wireless channel being a shared medium where collisions can occur and where a diverse set of physical effects can affect transmissions, the communication over such channels is inherently lossy. As a result, without proper error protection mechanisms data exchange under timing and safety constraints as imposed by the platooning application is not possible. To address this issue and ensure safe wireless data exchange we apply DDS/RTPS-based error-protection protocols to the platooning use case. Those protocols will also interact with the RM.


The following research staff are involved with the project at TU Braunschweig: